最近有朋友想爬虫抓取小红书上的图片:
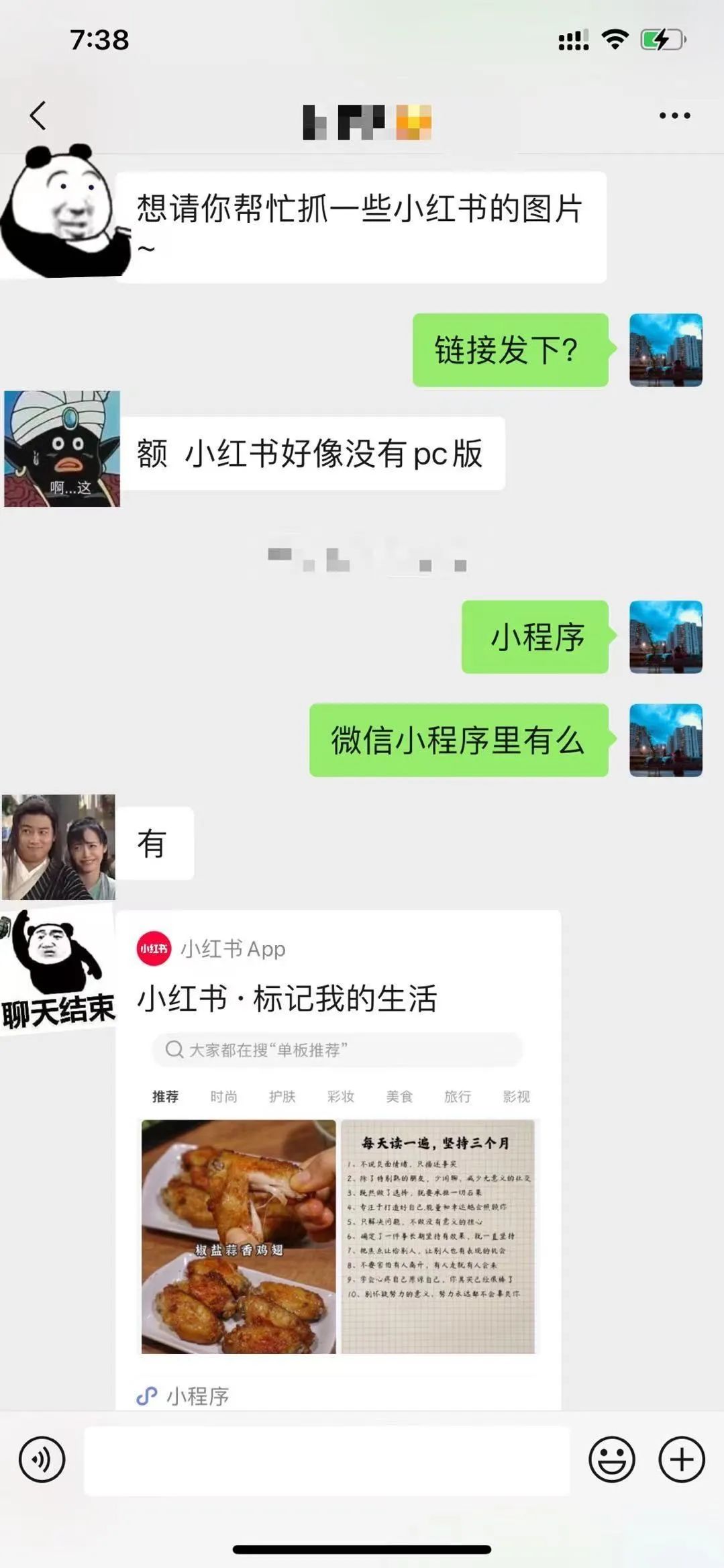
结合以往爬虫经验,抓数难度App>网页版>=微信小程序,所以我们选择小红书的微信小程序来突破。
通过charles抓包工具,在小红书小程序内点击各分类时,很容易定位到其请求和返回结果:
charles 抓包:
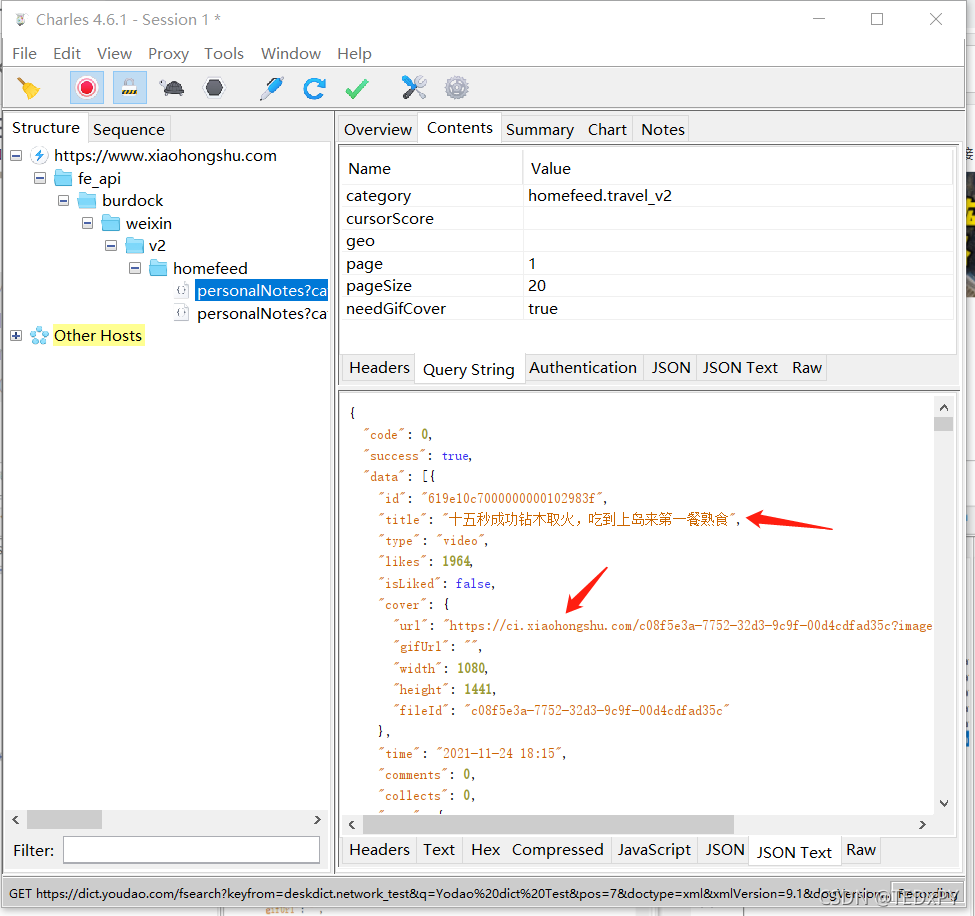
每次请求返回20条信息流,其中包含了我们想要的图片链接;当我们在小程序里不断往下滑动时,新的请求就会发送获取更多的信息流。我们要做的就是提取请求的参数,模拟发送请求、爬虫抓取返回结果、提取图片链接就ok了。
由于工作中我是使用 NodeJS 来爬虫的,顺手用 JS 写的爬虫代码;看文章的各位可能也只是看个思路,所以这里就不放具体代码了,参数里面有个比较麻烦的"签名参数" x-sign,这里着重说下:
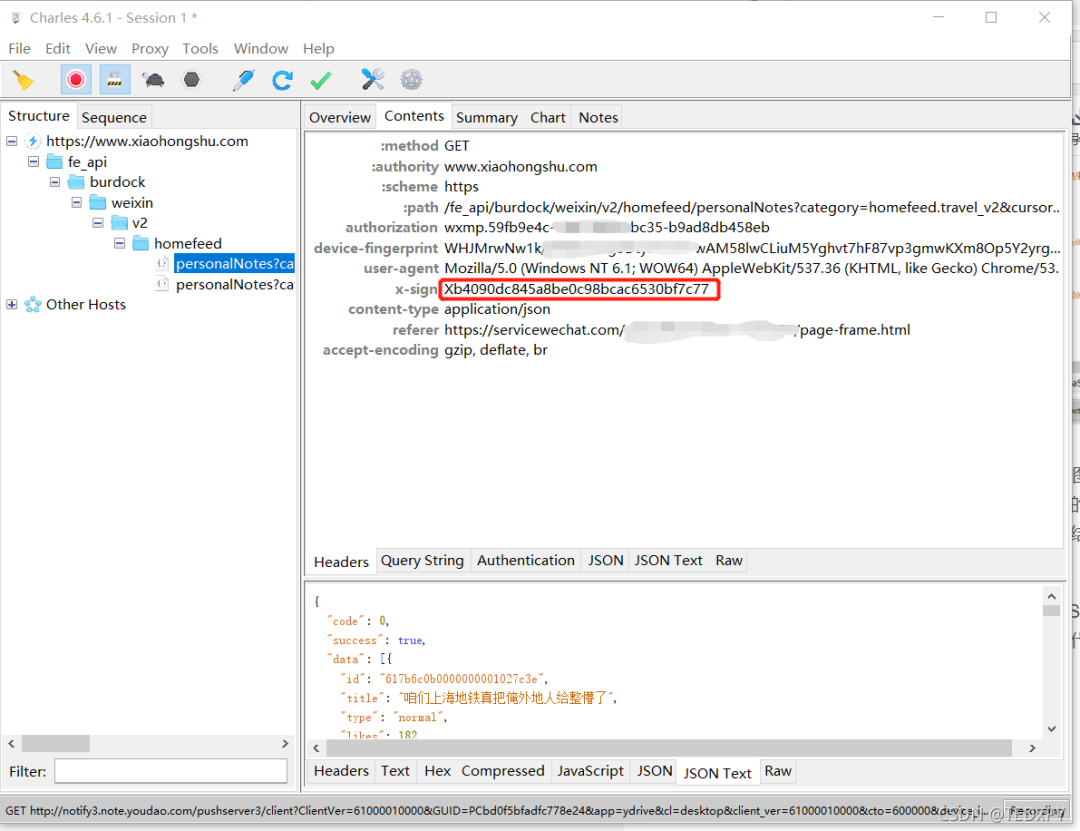
在网上搜相关内容时,确实有不少大牛把这个参数破解掉了:其格式是字母X加32位的16进制字符,通常32位16进制字符是MD5加密之后得到的结果,所以也比较容易猜测。但是吧,涉及到怎么解密,要么要私下联系作者、甚至还要收费给你破解。
最近正好我也在研究反编译小程序,成功破解了几个类似的小程序的签名参数,抱着试一试的态度,最终花了一小时把这参数给搞定了~
刚提到了,这个参数可能是用MD5算法对某些值进行处理后得到的结果,那具体的逻辑只有看源码才能知道。文章开头我又说过小程序是比较容易破解的,原因是微信小程序通过反编译是比较容易拿到源码的(可能不是完全的源码、但大致的参数逻辑通常是可以定位到的)。
1.反编译小红书小程序
第一步是反编译小红书小程序,定位到其x-sign参数生成的源码。这里反编译小程序我是参考如下帖子:
https://juejin.cn/post/7002889906582192158
大致流程是在登录电脑版微信,打开小红书小程序,找到小程序文件的目录,先解密再反编译,获取到小程序处理后的源码。
2.源码中搜索目标参数
因为我们是想获取 x-sign 参数的生成逻辑,所以直接在文件内搜索 x-sign:
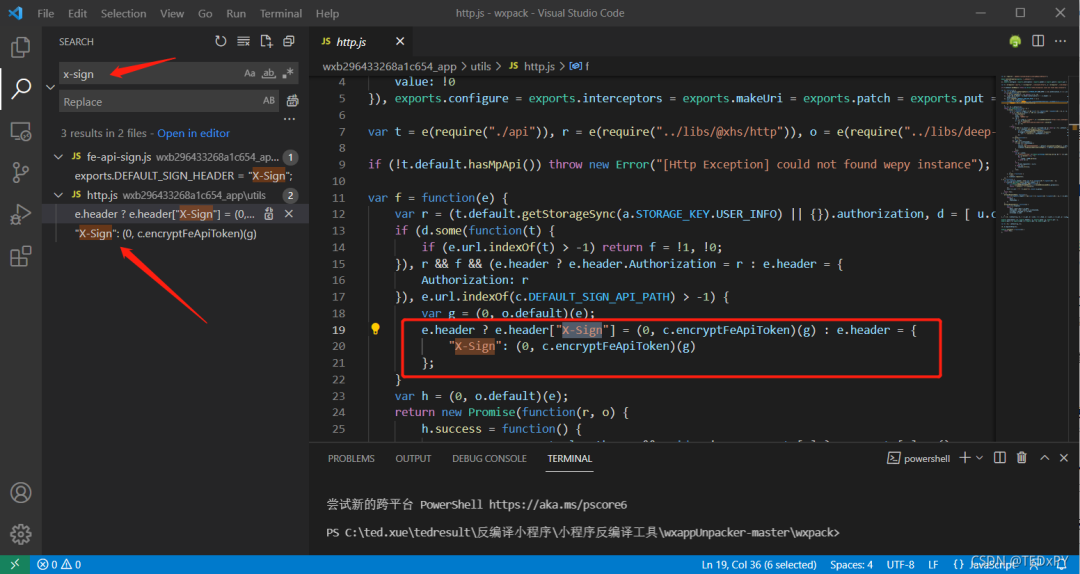
顺着红框里相关的函数名一路找下去,会逐渐发现它是把请求的参数进行拼接,再组合某个固定字符串后进行 MD5 处理,最终再开头加个大写的 X 构成 x-sign,整个过程和初始猜测是一致的。
3.模拟源码重新生成相关参数
以往我都是用Python自己琢磨爬虫,但工作中是用 NodeJs 爬虫抓数,渐渐也发现 NodeJS 其优势所在:一般网页前端代码是 JS 写的、像小程序里面这些加密逻辑也是 JS 写的,在进行模拟生成相关参数时,NodeJs 可以无缝衔接。我通常的做法是,无论其加密逻辑多么复杂,只要搞清楚输入的参数,我就直接把它的一堆加密代码全都复制出来,设置好需要的各项参数和变量,直接大力出奇迹得到结果
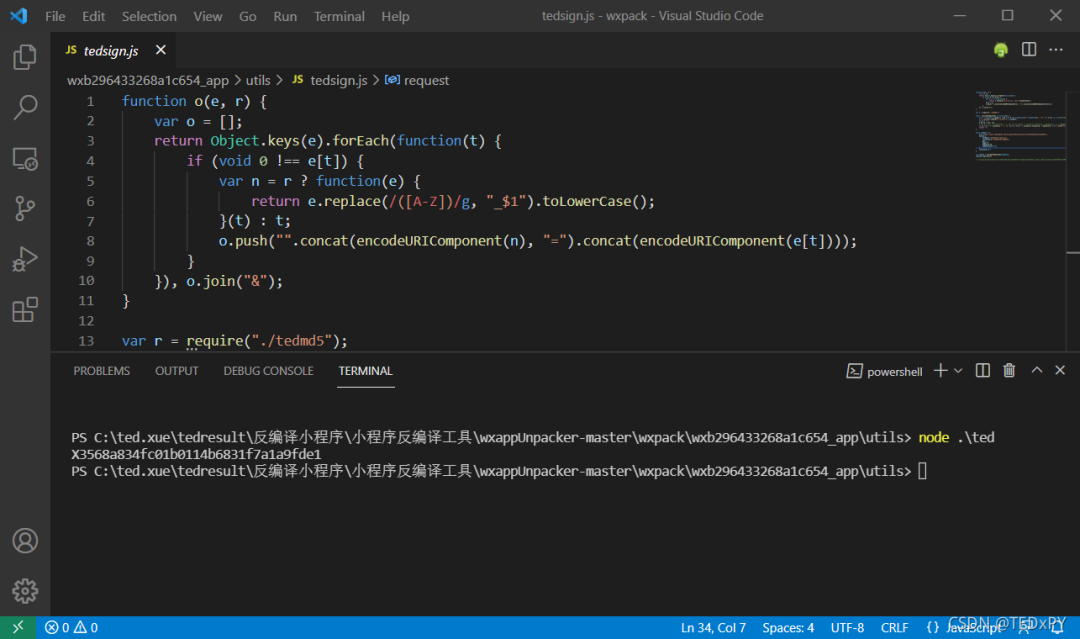
如图,我将源码中生成 x-sign 参数的函数和变量们配置好之后,直接运行得到了给定某些请求参数时所需要的 x-sign 值。
4.配置参数进行爬虫
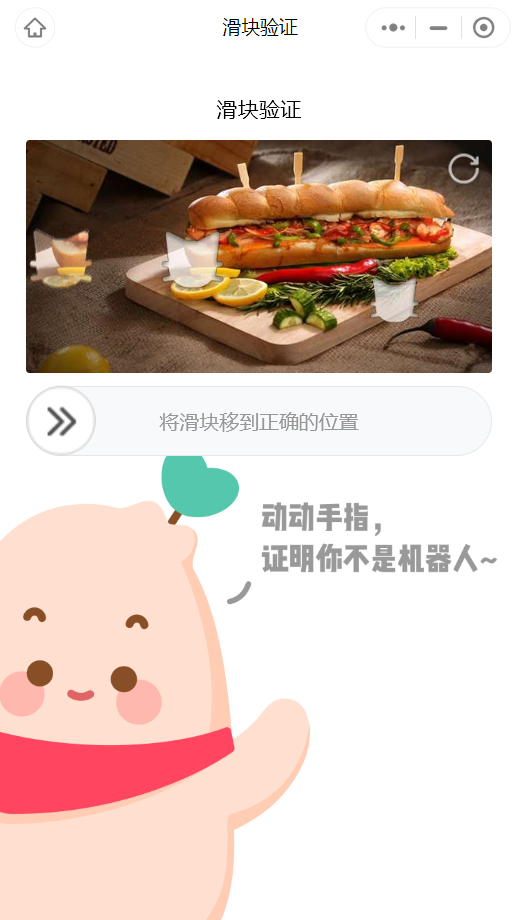
拿到 x-sign 之后的爬虫就是中规中矩流程了,每次请求得到20条,不断翻页获取更多。但小红书毕竟是大公司出品,反爬措施还是有的,比如抓取返回500条后会触发滑块验证:
以及返回1000条信息之后就不再返回数据了:
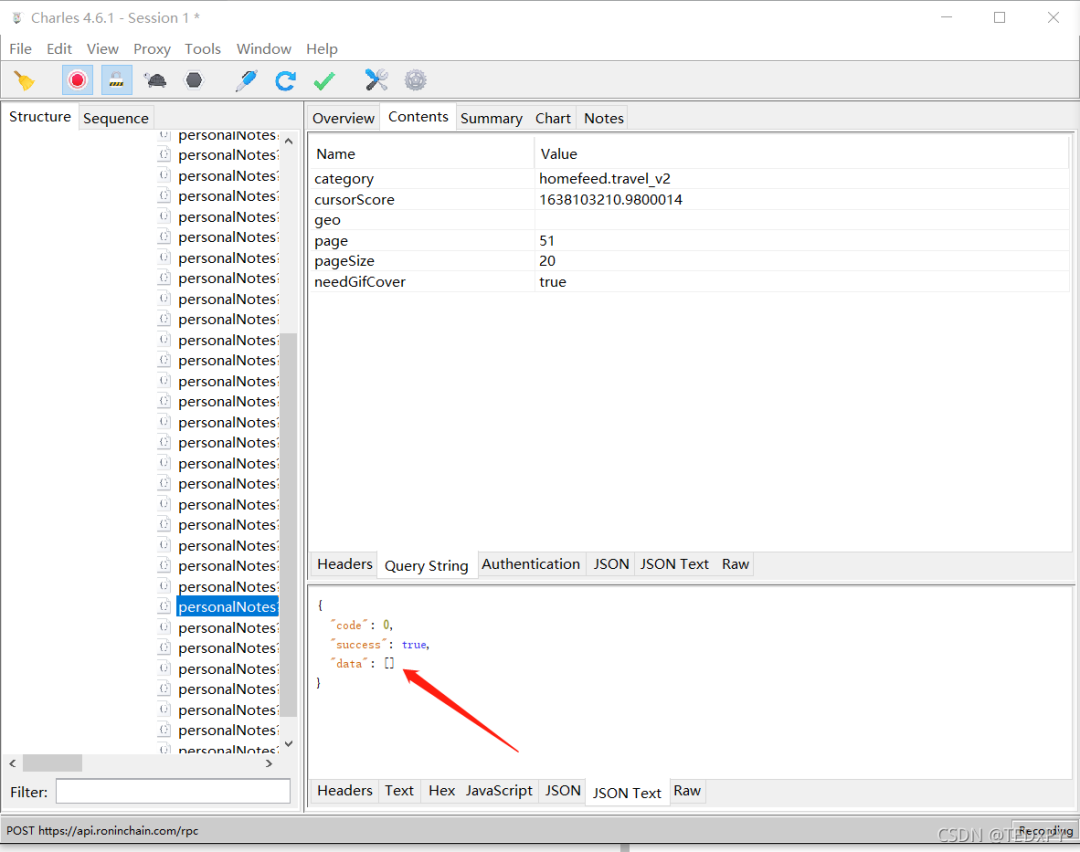
所以最终我们的爬虫只能实现每个目录下抓取1000条帖子内容和相关的图片链接。期间如果触发滑块,手动拖动滑块验证后程序仍可以继续抓取。
回到最初的需求,朋友是想抓取小红书上的图片,我们现在已经抓取到了图片链接,后续再写个批量下载的脚本即可——但已经有英雄登场了:
回顾整个需求,利用工作之余、耗时不到一天,还是蛮高效的!
反编译并破解加密参数的乐趣,尤其是通过独立研究完成了整个流程,都是蛮有意思的。



