解码小红书推荐系统:为什么在这里普通人更容易被看见?
出差期间,我在酒店百无聊赖地打开了小红书。一篇看似平淡无奇的笔记吸引了我的注意——一位 ID 叫「倚着彩虹看夕阳」的用户发帖,说自己在酒店的床上看西游记时,感觉到前所未有的放松。

从标题到配图,这篇发布于去年 5 月的笔记没有任何明显的爆点,但显然在小红书上引发了广泛的共鸣,收到了大量的点赞、收藏和评论。我也被吸引,陷入了#走不出的评论区。
现代人的信息获取方式很大程度上受推荐系统所影响,这篇笔记在发布 8 个月后依然能进入我的视野,小红书的推荐系统功不可没。相比之下,很难想象同样的内容在其他平台上也能得到如此广泛的传播。
为什么在小红书上普通人更容易被看见?它的流量算法,如何让每个人都有机会成为爆款文的主角?为什么身边人越来越爱刷小红书?
带着这些疑问,我走访了小红书技术团队,希望通过他们的解释,能更深入地了解这个让无数用户感叹「特别懂我」且「氛围极好」的内容社区。
重视普通人表达——小红书内容分发和推荐逻辑随着近些年用户和内容的快速破圈,小红书摇身一变,从「人间种草机」成为「生活百科全书」。作为一个基于用户生成内容(UGC)的生活指南社区,小红书融合图文、视频、直播等多种内容形式,内容维度非常丰富。推荐系统需要权衡多重目标优化,算法背后的价值观让小红书选择了不一样的技术路径——
去中心化分发、注重用户体验和社区的高质量互动,这也形成了其特别的内容分发和推荐策略。
小红书旨在创建一个「普通人帮助普通人」的内容分享社区,满足普通人的内容被看见的需要。有一个非常典型的案例凸显了小红书推荐系统的快速与准确,曾经有一位女孩在信号较差的火车上发帖求助卫生巾,仅仅两个小时后,她就收到了陌生人的神奇馈赠。在这里,任何人都可以分享他们觉得有趣或有用的生活细节,无论多么微小。
为什么我们在小红书上能看到这么多「素帖爆火」的案例,其中一个重要的影响因素是技术分发的逻辑。小红书的技术理念很独特,将大约一半的流量给普通 UGC 用户,让普通人的创作有平等被看到的机会。与此同时,这些普通人的经验与生活分享也会在未来逐步释放出长尾价值。
在小红书上,笔记被推荐的综合考虑因素很多,没有标准的公式一概而论。具体说,纳入考虑的因子包括点击、时长、完播、下滑、质量、点赞、收藏、关注、转发、评论等。小红书的推荐系统会根据用户的习惯调整各因子的权重,一般会综合考虑消费、互动和体验类指标,结合用户的消费行为偏好,实现个性化的权重组合。同时,小红书推荐系统也会根据笔记的发布意图来调整收藏、转发和评论的权重,例如,日常分享类的笔记更看重点赞,工具类笔记更看重收藏,求助类笔记更看重评论。
小红书上各种「被看见」的普通人普通事
当一篇新的笔记在小红书发布后,它将经历一系列复杂的处理步骤,通过「人以群分」的内容分发体系,把信息精准给需要的人。虽说当前各种推荐系统的核心算法和基本流程在很大程度上是类似的,但
与传统推荐系统追逐的「全局最优」不同,小红书将流量分层,寻求「局部最优」,通过识别不同的人群,让好的内容从各个群体中涌现出来,跑出了适合社区的新一代推荐系统。
那些素帖爆火背后的秘籍,无一不透露着:一个优秀的推荐系统,关键在于如何根据具体的应用场景、用户行为和反馈来调整和优化这些基本方法。
对小红书来说,关键的问题包括在冷启/爬坡阶段,如何进行内容理解从而定位种子人群并进行高效的人群扩散;在召回/排序环节,如何提升模型预测的精准度,以及如何进行实时流量调控;还有如何保证内容的多样性,使用户的短期兴趣和长期兴趣得到平衡。
挖掘长尾,高效分发——多模态内容理解内容理解是推荐分发的基础。精细和准确的个性化推荐,离不开对内容的充分理解,只有让系统真正掌握了到底内容在讲什么,才能够推荐得更加准确。传统的内容理解主要依赖于标签化体系,然而,这种体系的主要问题在于标签粒度过大和标签维度过窄。在小红书这样海量且多样性强的内容场景中,这两个问题尤其突出。无论如何定义标签体系,都难以覆盖多样化、长尾化的内容,同时,标签体系的运营更新也难以跟上内容的迭代和发展。
为了解决标签化内容理解体系的问题,小红书技术团队借助大规模多模态预训练模型,构建了向量化的内容理解体系。这种向量体系具有更开放的通识知识和动态自由的使用方案。作为传统标签体系的补充,向量化系统通过隐性聚类能力实现了细粒度、动态化的内容分类;另一方面,通过预训练和微调的方式,提高了系统在更多维度上对内容识别和评价的精度。
在多模态预训练方面,团队采用了类似于 CLIP 的对比学习,在经过清洗和去噪的小红书笔记样本上进行训练。小红书是一个天然的优质多模态图文对样本集散地,通过将笔记封面图和笔记标题组对的方式,不需要人工标注,就能获得数以十亿甚至更大的样本集合,保证了样本的规模性、多样性和时效性。在优质样本的支持下,团队开发出了参数量从 10M 到 10B 不等的各种 backbone 选型,支持 BERT、RoBERTa、ResNet、Swin-T、ViT 等架构,以满足下游的各种使用需求。
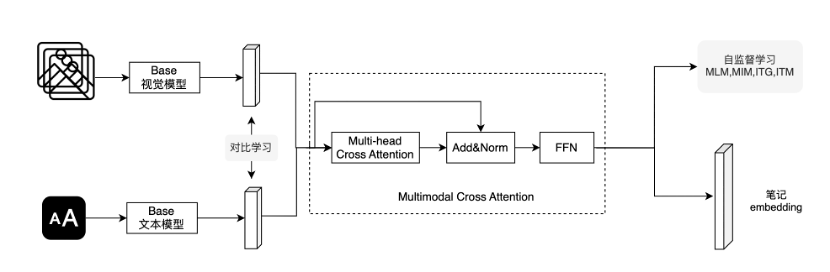
以多模态预训练向量为基座,实现对复杂多模态内容的综合语义表征
在应用实例上,团队实践了基于笔记多模态向量的层次化内容聚类,用于 Feed 的多样性打散。通过向量聚类得到的 ClusterID 作为隐性内容标签,并通过调整聚类相似度门限来动态控制 ClusterID 的粒度,从而实现自由粒度上的相似内容打散和频控。
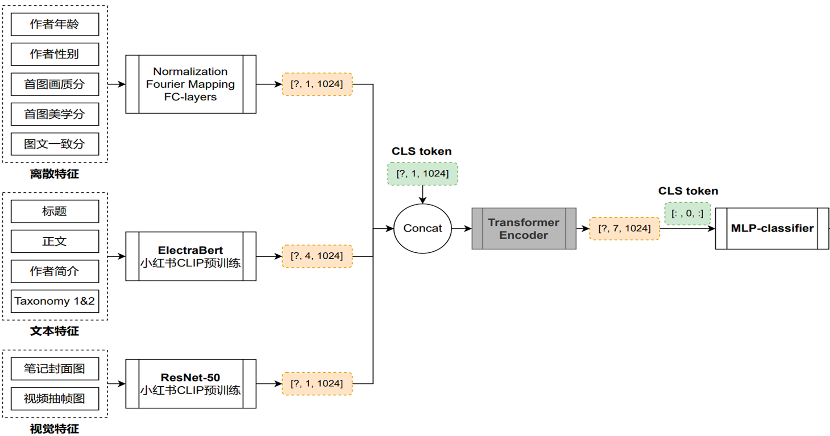
基于纯静态内容特征刻画笔记质量,实现冷启/长尾优质内容高效分发
同时,团队利用内容的后验分发数据(例如点击率、点赞率、快划率等),对预训练向量进行微调,从而实现对内容分发质量的级别预测。小红书开创性地构建了一整套内容质量框架,利用封面图片画质美学模型和多模态笔记质量分模型,定义有用和美好的内容。由于内容分发质量完全聚焦在内容的静态特征上,因此在冷启动和长尾内容推荐上更为有效,不会受到马太效应的影响,避免了推荐趋向于热门内容的问题。
新笔记冷启动,种子人群识别——去中心化分发的基础小红书发现,扶持新发布、低曝光的笔记可以增强作者的发布意愿。在全域曝光中,大约一半的流量分发是普通用户发表的内容。优质、有价值、引发共鸣的内容永不过时。小红书推荐分发还具有独特的中长尾流量效应。哪怕一条笔记的初始数据一般,只要它有价值,系统捕捉到中长尾信号,依然会被推荐给需要的用户,与发布时效无关。
一个素人博主没有多少粉丝,创作的内容都有可能成为爆款,帖子点赞量或收藏数上千。在前文「酒店的床上看西游记」的例子中,发帖的用户粉丝量少,主页互动内容也不多,如何对其进行推荐和展示?
这归结为推荐系统的一个核心问题——新内容的冷启动。冷启动的问题本质是在行为数据比较少的情况下充分理解内容,从而实现更精准的推荐,一般会被建模为一个 Regret Minimization 问题,主要关注如何最小化奖励函数的损失值。其中,奖励函数的估值标准至关重要,因为它反映了每个平台的不同价值选择。
多数平台会选择消费类指标,如点击率和停留时长,作为奖励函数的评估标准。相比别的平台,小红书具有更强的 UGC 生态,社区属性更强。所以,在冷启动阶段,系统更加关注高质量评论的数量、挖掘高潜笔记,因为高质量的评论数量反映了目标人群对新内容的互动情况,也即新内容是否被准确分发到了符合其特性的人群中。
在新内容冷启动问题方面,小红书技术团队形成了一套包含 4 步的 pipeline:
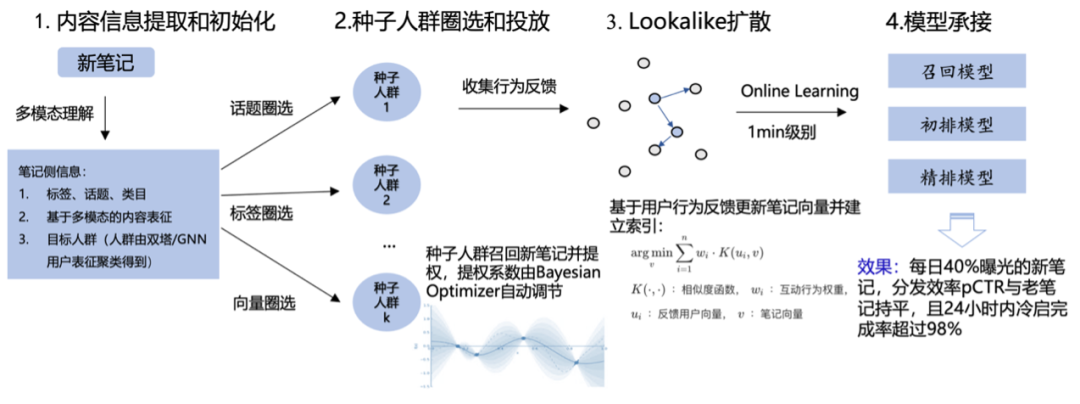
1、内容信息提取:新内容刚上传时,没有用户行为信息,只能通过内容信息进行分发。技术团队运用 NLP、CV 和多模态融合技术,提取内容信息,生成相关的话题和内容特征。
2、种子人群圈选和投放:团队利用内容信息定位目标人群,这些人群是通过双塔模型和图神经网络产出的用户 Embedding 进行聚类得到的。然后根据内容信息,判断哪些人群对新内容更感兴趣。新内容在种子人群中的投放,借助贝叶斯寻优调整 boost 系数,以找到用户指标损失和新内容曝光的最优权衡。
3、基于行为反馈的人群扩散:在初期分发后,新内容会积累一定的用户反馈。小红书希望将这些新内容也分发给与反馈用户相似的其他用户。他们通过 lookalike 模型进行人群扩散,根据与新内容有过交互的用户向量生成新内容向量,并将其作为向量索引。通过定义不同的用户向量和新内容向量的相似度函数,小红书推荐系统 lookalike 模型的点击率提高了约 7%。
4、模型承接:在完成初期的冷启动后,新内容进入正常分发阶段。模型的时效性决定了模型是否能有效处理新内容。通过持续迭代,目前小红书首页推荐的召回、粗排和精排模型的训练都做到了分钟级更新。
最终的效果,小红书已经实现了每日新内容占 40% 曝光,新内容的分发效率(pCTR)与老内容持平,且 24 小时内冷启动完成率超过 98%。
推荐多样性,长短期兴趣的平衡——兴趣的探索和保留在小红书 APP 首页,会用「发现 Explore」定义信息流推荐的场景,希望能够帮助用户发现感兴趣的内容,或是找到新的兴趣。在「发现」这一目标的驱动下,多样化的推荐显得尤为重要。
用户的兴趣是多样化的,并且会随着时间的推移而变化。这些变化可能体现在一天的早晚,一年的四季,或者人生的不同阶段。因此,小红书的推荐系统不仅要提供用户当前感兴趣的内容,还要积极探索用户可能感兴趣的新领域,以更好地满足用户的期待。
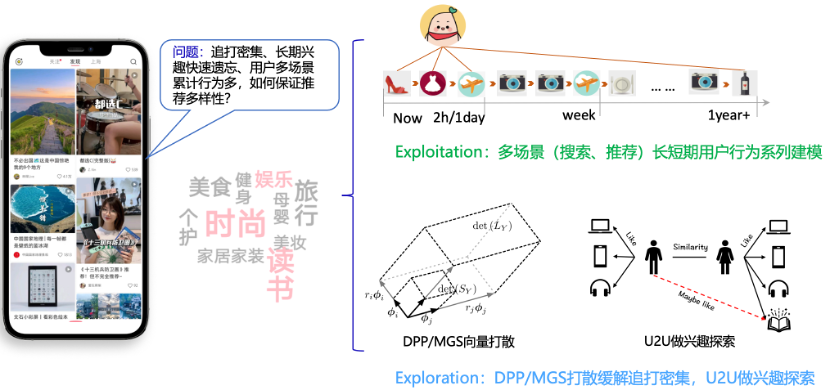
为了达到推荐多样性的目标,小红书推荐系统引入了两个关键策略——精细化信号利用(Exploitation)和探索(Exploration)。在精细化信号利用中,系统对用户在多个场景(如搜索、推荐、个人页和作者页等)的各种行为进行精细化利用,归因不同场景不同权重,并根据用户的行为历史进行序列化建模(实时、近一天、近一周、近一个月、近一年)。这种方法提高了模型对用户兴趣的捕获和刻画能力,有助于满足用户的短期兴趣。
在探索策略中,系统使用 DPP 和 MGS 等向量打散机制,解决追打密集导致的实时兴趣内容过量、长期兴趣快速遗忘的问题。同时,系统通过人群召回来解决兴趣探索问题,有助于发现并满足用户的长期兴趣。
为了平衡推荐质量与多样性,小红书提出了滑动频谱分解(Sliding Spectrum Decomposition,SSD)模型。在信息流推荐场景中,SSD 模型通过高效的滑窗计算,将单篇模型的价值排序转化为整个浏览周期的建模。
在多样性的定义中,需要利用 Embedding 来计算内容的相似度。相对于头部内容,中长尾内容的用户交互数据更加稀疏,传统的协同过滤方法在计算相似度时效果不佳。因此,团队设计了一种基于内容的协同过滤方法(CB2CF),使用内容信息预测协同过滤的结果,更有效地衡量中长尾内容的相似性。CB2CF 方法仅使用内容作为输入,依赖模型的泛化能力为新内容提供良好的预测结果,同时依赖全体用户的协同标注获取用户感知的信号,从而提高推荐质量。
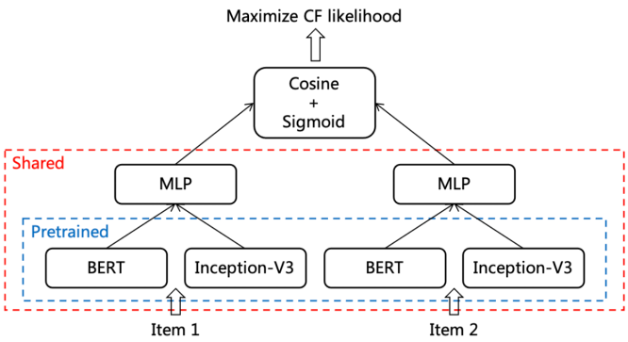
CB2CF 的思想源于微软 2019 年发表在 RecSys 上的工作。小红书在此基础上改进了 loss 的构造方法,取得了更好的结果 [1]
大模型时代,推荐系统的下一站作为近年来增长最快速的移动互联网平台之一,小红书证明了推荐系统可以兼顾用户价值和平台利益。当用户在平台表达自己的偏好,如对哪种类型的内容感兴趣、希望看到和不希望看到哪些人或事等,推荐系统会精准的感知并不断调优来满足用户需求。这样,用户的满意度提升,社区持续长大,平台的流量价值和商业利益就在其中自然而然地生长起来。
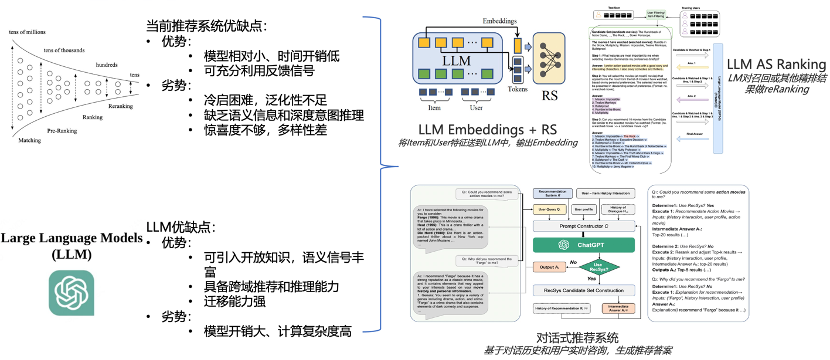
在大模型时代,推荐系统正面临着前所未有的发展机遇。大模型具有强大的泛化能力和知识理解能力,可以为推荐系统带来更精准的推荐结果、更好的用户体验,以及解决实际问题的能力。然而,大模型在推荐系统中的应用也面临着诸多挑战,如计算资源需求、模型可解释性等。
随着大模型的蓬勃发展,小红书的推荐系统将如何演进?
大模型时代推荐系统的机遇和挑战
目前,在推荐系统与大模型结合领域,存在两种技术路线:一种是将大语言模型(LLM)发展或改造成为一个推荐系统,另一种则是将现有推荐系统与 LLM 结合,例如将 LLM 作为特征编码器,或者作为推荐 pipeline 的控制/调度模块。
在第一种路线上,小红书进行了一系列的尝试。现阶段而言,主要挑战在于处理速度过慢。尽管输入的参数有时会带来出人意料的结果,但这种方法与长期积累的推荐系统工具和算法之间存在断裂。小红书技术团队发现,如果完全依赖于 LLM 进行推荐,那么推荐性能将从一个相对高的行业基线跌落。因此,小红书技术团队目前更偏向于后者,也即在推荐系统的传统流程中融入 LLM 的功能,他们认为这是一个极具潜力的研究方向。
总的来说,推荐系统与大模型的结合具有巨大的发展前景,特别是让用户能够接受和系统进行多轮交互这一点,与传统搜推系统场景不同,大多数用户都愿意与 ChatGPT 等 LLM 多聊上几句,让推荐系统有了更多机会去学习和了解用户的意图和需求,而传统场景下用户在最初一两次搜索没有得到想要的结果后便会离开。因此,对于有明确业务场景的公司,可以在大模型时代挖掘出新的机会。
结语在网络内容爆炸的当下,小红书的推荐系统通过其独特的算法和设计,为普通人提供了一个发现和被发现的平台。这种理念背后的用户导向和社区价值,让每个用户的声音都有可能被放大,成为共鸣的起点。
随着技术的发展,推荐系统需要更多人性化的考虑,例如,如何在确保内容质量和保持算法公正性之间找到平衡,如何避免让不具备长期价值的内容被过度放大。大模型时代,推荐系统的可解释性和透明度如何增强,也是一个重要的挑战。
在小红书的案例中,我们看到了技术如何助力构建更加平等和多元的内容生态,这个过程中的技术抉择和价值考量是推动社区长期健康发展的关键。对于用户而言,思考这些问题,不仅是享受个性化内容带来的便捷,也是理解和参与未来数字社会的重要一步。
注释[1] 论文:Sliding Spectrum Decomposition for Diversified Recommendation,https://arxiv.org/abs/2107.05204












