编辑导语:分析小红书的算法,可以产品角度出发,也可以从运营角度出发,而本文作者则是从技术角度出发,对小红书的算法进行了分析。感兴趣的小伙伴们,一起来学习一下吧。

这是一篇哈佛医学院的HMS学术文章,一个叫Nsoesie和他的小伙伴们分析了医院停车场的车辆数量和互联网搜索趋势,得出了疫情最早在19年8月在武汉开始。当然这一说法被哈佛医学院自己否了,理由是不适当和不充分的数据、对统计方法的滥用和误解,以及挑选互联网搜索词。事情并没有随着问题的发现终止,Nsoesie这些人的说法得到了媒体的广泛报道。
我们来把整个时间进行简单概括,大致就是——很多数据说明医院里的车多了;车多了,肯定是看病的人多了;看病的人多了,肯定是得了新冠肺炎;同类类比,南京中华门景区旁边是市第一医院,直线距离1.1公里。除了一个小停车场、一个巷子、医院地下停车场,没有其他停车位,小停车场和巷子日常是停满了的。国庆假期到了,医院停车场满了。得出的结论是——南京爆发疫情了。
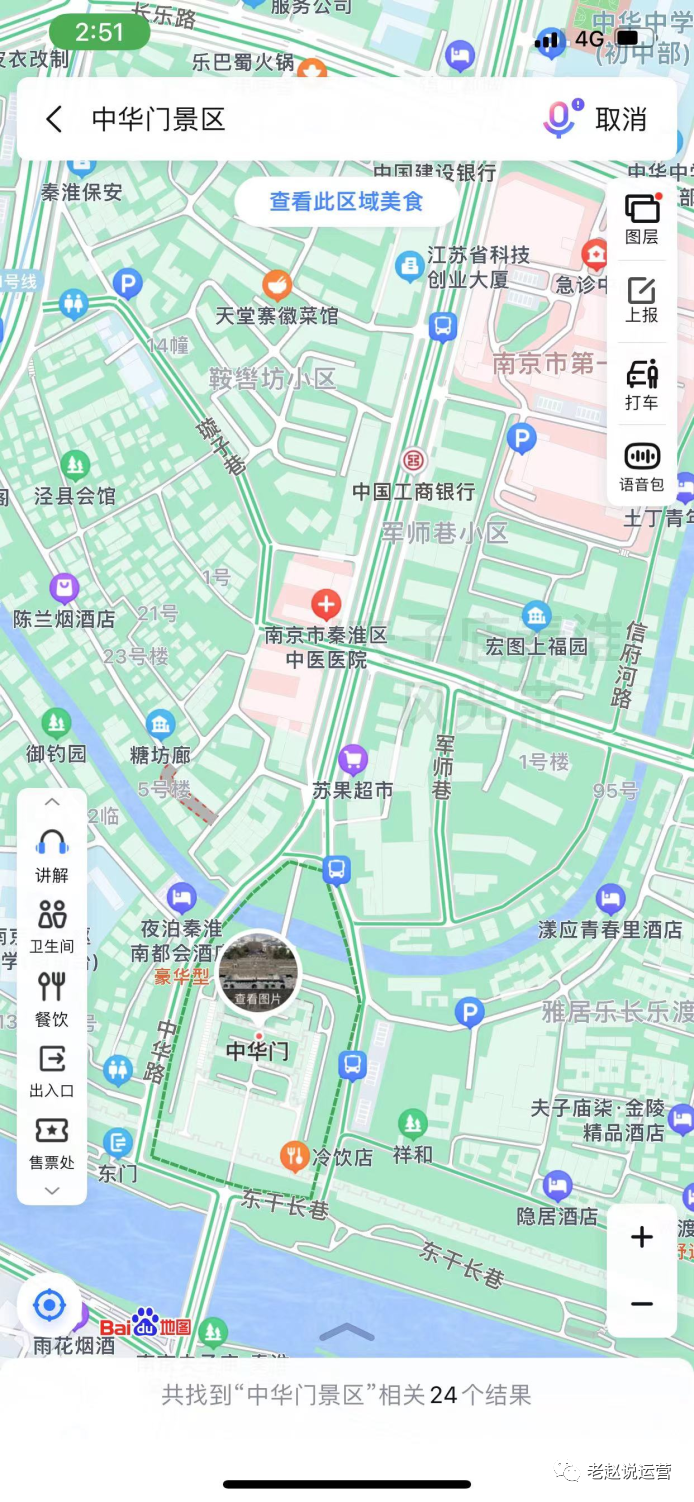
如果从现象推原因,事实会差多少?上不了台面的科研骗局,但是用脚投票的大众选择相信,不相信的人却别有用心地传播。
对应到运营行业中,是不是很像整天方法论、刀法、套路、核心、SOP的某些人?从结果拆方法,方法汇总复用告诉100个人。只要有1个人做好,就可以说“你没有做好,别人能做好,是你的问题”。哲学中有个朴素的观点是“实践是检验真理的唯一标准”,而实践之所以作为真理的检验标准,这是由真理的本性和实践的特点决定的。
做火了一两个账号/甚至没做过账号,总结出的运营经验语句都不通顺,前后经不起推敲,而大家已经掏钱上车了。如下图,其实所有需要分发内容的APP都是这个逻辑。

所以这篇内容我不会写那些网上一搜就会搜到10篇有9篇一样的小红书算法内容,同样和上篇内容一样做不到通俗易懂,甚至枯燥,看了不知所云。但相信我,看完你们会有很大的收获。也许业务中的一些小的问题终于得到确认,可能看待小红书运营的角度更加的多元化,或者学会了更加具象的思维。
想听刀法、方法论、扯淡的可以点右上角的×了,如果你们想从更底层去一点点认知自己在做的平台,这篇内容如果对你们有帮助那就太好了。我扒了很多论文、论坛以及找来了不少小红书公开演讲的PPT梳理总结,与实际业务相结合,欢迎关注点赞留言。
01很多人经常说小红书算法,大部分人从产品角度出发,少部分人从运营角度出发,几乎没有人从技术角度出发。
算法是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。定向A➡定向B,可能是男性和女性,也可能是国王和皇后。我们应该先解释A和B,而不是讨论怎么从A➡B。
从产品角度出发没有什么大问题,但是有两类大点,即产品的背景及使用。产品的背景包括解决什么需求、具体的使用场景是什么样、目标用户是什么。产品的使用包括体验、UI、美工、交互。我看了大多数人对小红书算法的分析,是从UI角度出发,即使用者界面出发,其实是相当不准确或者说浅层次的。
从UI角度出发,抖音和小红书相似程度是非常高的。抖音的首页-推荐、关注、同城和小红书的首页-发现、关注、同城基本一致,消息页和我的页面也基本一致,那么算法和逻辑就一致吗?
差的太多了,反映到结果上,我们抖音和小红书同样的都做了200万粉左右,一个基本没有任何变现,一个收益很高。后来我们反复复盘,平台就像那些年我们追的女孩子,没有人永远年轻,但总有人正在年轻。即使运营了很多年,我们对当初的这个女孩也时常感到陌生。而平台也总会诞生新的机会,给后来者遐想空间。
话不多说,让我们简单的梳理小红书算法。不少段落取自ArchSummit深圳演讲-赵晓萌(小红书算法架构师,负责机器学习应用)、2019阿里云峰会·上海开发者开源大数据专场小红书实时推荐团队负责人郭一的发言、以及秦波(推荐引擎北京工程负责人)、马尔科(小红书大数据组工程师)的帖子/PPT。如有侵权,联系修改或者删除。
小红书社区是一个分享社区+电商的APP,分享社区通常意义上都是以女性为主,少量话题引导。每天平台生产的内容,要如何转发分发给用户,让用户看到用户想看的,这是算法需要解决的问题。
对于小红书来说,社区提供用户黏性,为电商引流,电商把这部分流量变现,在APP里形成闭环,社区和电商互相推动。对于算法团队来说,有社区的用户数据,有用户在电商版块的行为数据,如何把两边的用户行为连接起来,更好的理解用户,是算法的根本出发点。
现在大家普遍认可的都是下面这个流量分发模型,系统根据用户互动效果进行评分的体系是CES。实际上太笼统了,CES评分也不知道是出现在整个推荐流程中的第一步、第二步、第三步,还是反复计算。接下来我会通过具体的一些案例,从技术的角度去解释。
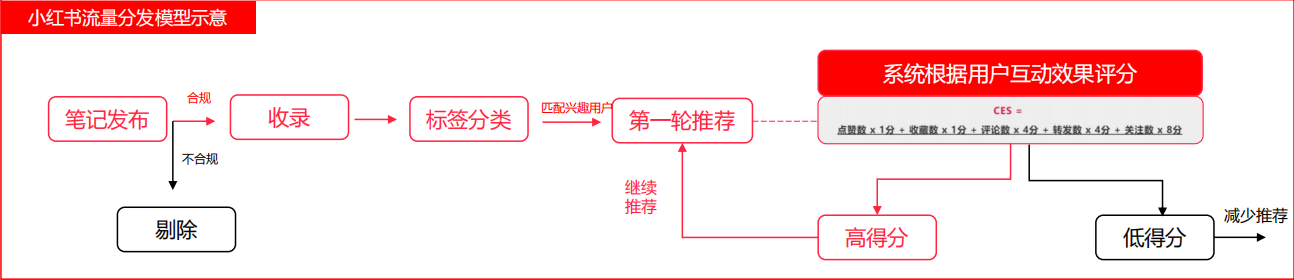
如果有看过我上篇讲搜索流量的小伙伴应该有印象,一篇笔记的搜索流量相对稳定占位,而推荐流量是笔记成为爆款的核心。小红书线上推荐的流程主要分为三步:
从小红书用户每天上传的笔记池中选出候选集,通过各种策略从千万条的笔记中选出几千个候选集进行初排。
在模型排序阶段给每个笔记打分,根据小红书用户的点赞和收藏行为给平台带来的价值设计了一套权重的评估体系,通过预估用户的点击率,评估点击之后的点赞、收藏和评论等的概率进行打分。
在将笔记展示给用户之前,选择分数高的笔记,通过各种策略进行多样性调整。

那么小红书是如何从每天的笔记池中选出候选集进行初排的呢?
小红书的内容图文并茂,用户产生的内容图片多,质量很高。用CNN(卷积神经网络)提取图像特征,用Doc2Vec(文本到向量模型)提取文本特征,通过一和简单的分类器就能把用户分到主题中,而主题是人工标定的上百上千个主题。这是初排。
03CNN和Doc2Vec具体是怎么提取笔记进行分类的?
关于图片的识别,小红书是一个非常视觉的社区,图像很多,小红书用图像提取特征就已经能达到良好的效果,准确率大概是85%时覆盖率能达到73%左右。加上文本以后效果更好,准确率达到90%,覆盖率达到84%。
图片这是第一个在内容创作中需要注意的地方,对图像的夸张识别到什么程度?
我们有一次发幼儿、中小学的教育案例,拍到了角落翻开来的书上关于母婴胎教类的两行字,肉眼都看不清,违规发警告说涉及到婴儿遗传等敏感内容,账号不被推荐3天。后来反复查找原因,才发现这个问题。
这里再举一个更常见的例子,涉及到了GBTD模型里的机器深度学习。小红书上流行分享治痘,有很多脸上有很多痘痘怎么治好的笔记,怎么把这些观感其实不适的内容推荐给要看的人是一个问题。
当小红书尝试用CNN model做这个事的时候,发现无论照片是全脸漏出、半脸、1/4脸甚至只有少量的脸部器官,都可以很好地识别甚至识别图里的文本,对反作弊有一定的帮助。所以,不要在图片上进行任何夹带私货,图片识别+图片文本识别,基本上准确率有90%。
再讲一下文本的向量表示,文本的向量表示有非常多种,其中一个比较有名的向量表示叫做Word2Vec,是Google提出来的。它的原理非常简单,其实是一个非常浅的浅层神经网络,根据前后的词来预测中间这个词的概率,优化预测的时候模型就得到了词的向量表示。
同样的这个词的向量表示在空间里也是有意义的,相似的词也处在相近的空间里。这个模型比较有意思的是,把向量拿出来随时可以做向量运算。
女人到男人之间的那个指向的向量,和皇后到国王之间是一样的,所以我们知道其中三个,就能算出另外一个。假如我们的笔记重点是“自驾”和“露营”,Word2Vec会据前后的词来预测中间这个词的概率,可能是装备、路线、西藏、过夜、海边、周边、攻略,推送到对应的用户页面。
04用户画像和笔记画像是什么?在算法中扮演什么角色?

主要有9个预测任务,包括click、hide、like、fav、comment、share、follow等。点击、保持、喜欢、评论、分享、关注。点击是小红书最大的模型,一天大概产生5亿的样本进行模型训练。GBDT模型中的笔记分发,有非常多的用户行为统计,产生了一些静态的信息和动态特征,用来描述用户或者笔记。
通过用户画像和人口统计信息来描述用户,比如性别年龄这些静态信息。笔记分作者和内容两个维度,比如作者打分、笔记质量、标签、主题。动态特征虽然不多,但是非常重要。
动态特征包括用户在浏览和搜索中有没有点击、有没有深度行为等类似的用户反馈。这些交互的数据有一个实时的pipeline从线下直接放到线上的模型里,在线上会利用这些数据对点击率等交互质量的指标进行预测,然后根据用户和笔记的隐形分类进行推荐。
2. 关于动态特征的提取,小红书用的是Doc2Vec模型,也叫做相关笔记相关笔记的要求是什么?推荐的笔记和用户在看的笔记,最好讲的是一个东西。比如说同一款口红、同一个酒店、同一个旅游城市、同一款衣服,可能不是一个酒店,但是是类似的酒店。
可能不是同一个旅游城市,但可能是类似的旅游城市,是不是很难理解?那我们再具体一点,我如果看的是亚特兰蒂斯这种级别的酒店,那么小红书就不会给我推荐格林豪泰,而是类似同等级别的酒店。如果我经常搜的是雪山/草原/沙漠,那么就不会给我推荐上海/北京/广州这种人文和城市景观突出的地方。
有一点需要注意的是,TFIDF model 虽然基本要求词是一样的,但它可以把一类笔记找出来,就是讲用户心理、描述用户心情的笔记,因为用户描述心情用的词汇很接近,所以这个方法也会把扩展的内容找出来。“绝绝子”是非常明显的一个语气词或者形容词,在小红书有461万+篇笔记。
最核心的实时归因场景业务,是如何制作用户的行为标签的?
用户画像比较简单,不会存在过多的状态,而实时归因是整个实时流处理中最关键的场景。实时归因将笔记推荐给用户后会产生曝光,产生打点信息,用户的每一次曝光、点击、查看和回退都会被记录下来。
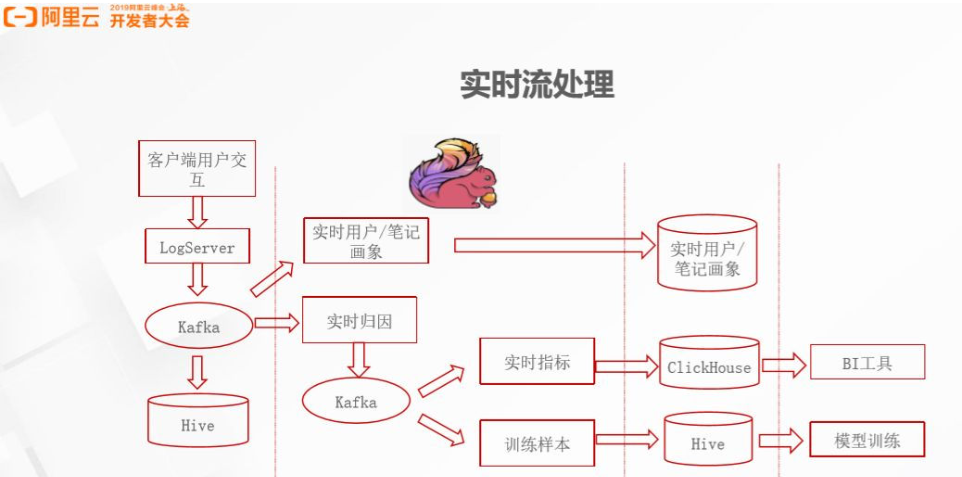
看一下下面这张图,四次曝光的用户行为会产生四个笔记曝光。如果用户点击第二篇笔记,就产生第二篇笔记的点击信息,点赞会产生点赞的打点信息。如果用户回退,就会显示用户在第二篇笔记停留了20秒。实时归因会生成两份数据,第一份是点击模型的数据标签,下图中第一篇和第三篇笔记没有点击,第二篇和第四篇笔记有点击,这种数据对训练点击模型很重要。点赞模型也和上面几乎完全一样。

CES评分参与在算法中的什么阶段?
整个线上推荐的流程,只有在模型排序阶段给每个笔记打分。笔记在笔记展示给用户之前,小红书会选择分数高的笔记通过各种策略进行多样性调整。
Score=pCTR*(plike*Like权重+pCmt*Cmt权重……)
CES如果参与其中,只是非常小的一部分。我通过爬虫把爆文笔记爬了下来并做成CES形式的Excel表格分析,无论是表现各项数据关系的散点图还是曲线图,都没有一个有规律的图表,所以CES最多用在冷启动,聊胜于无。
06综合以上,最后我们还是用比较通俗的话去解释这篇内容想要论证或者体现的观点:
小红书算法是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。不应该从使用者界面或者从已经成熟的账号中去梳理总结方法论,因为梳理总结的只是一系列机制中特别琐碎的小点,更不应该形成所谓通用的方法论。
大家工作业务开展也是,很多运营文章一下子就把整个运营流程说全了,我更建议从算法开始了解,工作也是从你实际的理论和认知中开展,并不是照葫芦画瓢。给你飞机让你照葫芦画瓢,好的,你来造。
不要做公司想要推广的内容/你喜欢的内容,而是要做算法觉得用户想看的内容,毕竟算法需要解决的问题就是——把平台生产的内容,转发给用户,让用户看到用户想看的。
对于小红书,算法的出发点是如何把社区的用户数据和电商版块用户的行为数据链接起来。现在小红书的盈利模式主要集中在达人种草,其实是算法团队不够优秀,没有办法提供足够优秀的中台支撑。无论是电商或者广告,其实大家都怨声哀道。
前台主要面向客户以及终端销售者,实现营销推广和交易转换。中台主要面向运营人员,完成运营支撑。后台主要面向后台管理人员,实现流程审核、内部管理以及后勤支撑,比如采购、人力、财务、OA等系统。
算法岗在各大公司招聘线中也是发OFFER最高的一档,目前来看,想做视频内容电商的算法人才会倾向于去抖音和快手。想做传统电商的,会倾向于去阿里或者拼多多。至于图文和纯文形式的电商或者广告,其实各家做了很多年都做的不是特别好。小红书图文能做好,得益于70%的用户群体是女性,社区氛围搭建的生活氛围非常精致。
选择合适的内容很重要,如果内容小众又刚需,那么小红书通过策略选出的候选集相对容易选到我们的笔记。在整个笔记出现在大批量用户的过程中,我倾向于CES评分没有参与在内,预测模型实际上扮演着很大的作用。体现在实际运营中就是,一张图片一句话的笔记火的一塌糊涂、老账号发什么什么火,因为预测模型。
小红书算法对图片的优先级非常高,并且有至少85%的准确率。如果加上文本以后,准确率能达到90%。所以无论是正常的图文、下水不报备的笔记、违规引流的笔记,算法一直是可以清晰无误地查出来的,只不过是运营中台对账号处理的松紧程度有关。例如哪个月要封账号,哪个月要查资质,哪个月要抓引流,算法都有数据,人为去干预就好了。
关于文本的动态特征提取,大家可以重点看一下上面说的预估词以及相关笔记,是一个非常有趣但是又很实用的模型算法,我从普通用户的角度,觉得抖音和小红书这块做得很不错。
小红书算法对笔记内容的好坏,取决于用户画像和笔记画像。用户画像一般是静态信息,注册账号的时候就完成了一大半,性别年龄这些。笔记画像包括做着打分、笔记质量、标签、主题(主题是我上面提到的人工分类的几百个算法里的主题,并不是下面带的标签或者内容主旨)。
在我们浏览推荐页的时候,可以多看看一屏的内容(四篇笔记),特别是用别的账号刷到自己账号的时候,如果一屏还有其他和你一样类目的笔记,重点研究,算法认为你们各方面都差不多,都展示了给用户看。
本文由 @老赵说运营 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
收藏已收藏{{ postmeta.bookmark }} 点赞已赞{{ postmeta.postlike }}



